Dewdrop Farm - A Post-Mortem
Dewdrop Farm was my entry into the 2020 js13kGames competition. It’s a tiny farming simulator, with an intentionally addictive compulsion loop.

You can play it online at 2020.js13kgames.com/entries/dewdrop-farm.
This is the 9th year I’ve entered the competition, but the first time I’ve written a post-mortem about my game development process. I took the notes I had in my development diary, and flushed them out with descriptions of what I was thinking about, example code, and screenshots.
Week 1st
The only real idea I had going into this, was “Make a game where the passage of time matters.” I usually pick some technical topic I want to learn about during the competition, and build a game around that. Having never done a game where the world runs independent of the player’s actions, I thought that would be an interesting thing to build.
I was playing Drop7 on my phone in the days leading up to the competition. The designer of that game, Frank Lantz, also made Universal Paperclips, an incremental game. So I played that, and read the paper Playing to Wait: A Taxonomy of Idle Games, and thought a lot about idle games. The 1.16 Nether update to Minecraft had recently been released, so I also had piglin bartering mechanics on my mind. I figured making a game with an economy would be interesting.
That combination of ideas reminded me of SimFarm, a game I loved as a kid. I got it in my head that I would build a mini version of Minicraft, just the farming and trading bits, rendering with a top down view so I didn’t have to also learn 3D maths while learning about game economies.
Googling Graphics
Searching for “farm” on OpenGameArt.org turned up a crop tileset by josehzz. That ended up defining the color palette I used for the game, AAP-64 by Adigun A. Polack, and also the look, 16×16 pixel sprites.
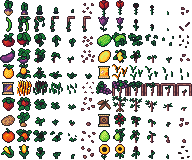
Once I found those crop graphics, I started thinking of Stardew Valley. Using Eric Barone’s game as a reference point got me through the first week of coding. The player has two tools, a hoe and water. Land needs to be tilled with the hoe before seeds can be planted. Crops grow at various speeds. Watering crops makes them grow faster. Land that’s watered dries out over time. Mature crops can be harvested and sold. Coins can be used to buy seeds to grow more crops.
Idling Away
I wanted Dewdrop Farm to run even when you weren’t actively playing it. So I used Jake Gordon’s article on render loops as a starting point. The game runs in fixed time, with an update taking place every 1/20th of a second.
I spent a fair bit of time in those first few days figuring out how long each “day” on the farm should last. I thought a lot about this quote by Eric Barone about days in Stardew Valley:
“The psychology of it and how, by keeping the days short, it always felt like you had time fro ‘one more day,’ no matter how long you had been playing. Before you realized it, hours had passed.”
A day in Stardew Valley lasts 14 minutes, 20 seconds. I knew I didn’t want my days to last that long, but I started with that “14 minutes” as a reference, and keep tweaking the math until I found something that felt right.
const SEASONS_PER_YEAR = 4;
const DAYS_PER_SEASON = 28;
const SECONDS_PER_DAY = (14 * 60 * 3) / 28 / 4;
A day in Dewdrop Farm lasts 22.5 seconds. That’s long enough that when I watched the day counter tick, I felt like it wasn’t making progress. But it’s short enough that when I was actively doing things, like buying seeds, I found myself asking, “Where did the time go?” This also means that the growing season, from the start of spring to the start of winter, lasts about half an hour. That felt like a good length of time for a play session.
It was about this time that Rachel Wenitsky posted a thread on Twitter about walking simulators and other idle games. That got me thinking about compulsion loops. I knew I was building an adictive mechanic, so I wanted to create a very deliberate “It’s okay to take a break” point to balance that out. I decided winter would be a season where nothing grew. If you wanted to continue the game beyond one growing season, you’d need to take a 10 minute break.
Randomizing Growth
Even though the game ran at a fixed rate, I knew I didn’t want the crops to grow at a fixed rate. I wanted to recreate that Minecraft feel, where you come back to a field of wheat and find that some of it is ready to harvest and some of it needs a bit more time. At the same time, I wanted to keep the economic stability found in Stardew Valley. The player should be able to figure out that it takes four days for turnips to mature, that way they can decide if they have enough time left in the season to plant them.
What I ended up doing was randomzing the time in each day that each crop would
grow. With each update, farm.time is incremented by 1/20th of a
second. So I first figure out how many seconds into the current day we are.
const day = Math.floor(farm.time / SECONDS_PER_DAY);
const farmTime = farm.time - (day * SECONDS_PER_DAY);
Then, if it’s a new day, I slice the 22.5 second day up into 36 time buckets, one for each plot of farmland. So the first time bucket is between 0 and 0.625 seconds, the second time bucket is between 0.625 seconds and 1.25 seconds, and so on. I randomly assign each plot of farmland to a time bucket, and pick a random time within that bucket for it.
if (growable.day !== day) {
let plots = PRNG.shuffle(Farm.plots(farm));
const dt = SECONDS_PER_DAY / plots.length;
plots = plots.map((plot, index) => {
const min = dt * (index + 0);
const max = dt * (index + 1);
const time = PRNG.between(min, max);
return {
...plot,
time,
id: index,
};
});
growable.day = day;
growable.plots = plots;
}
During each update I check to see if a crop on a plot of land needs to grow. If it does, I dispatch a grow action. If it doesn’t, I save it to check again the next update.
const plots = [];
const remaining = [];
growable.plots.forEach((plot) => {
if (plot.time <= farmTime && shouldGrow(plot)) {
plots.push(plot);
} else {
remaining.push(plot);
}
});
growable.plots = remaining;
plots.forEach(({row, col}) => {
const growAction = {
tool: 'grow',
row,
col,
};
farm = Rules.dispatch(farm, growAction);
});
That bit of code ended up working nicely for making crop growth feel randomly predictable. I resued it to also decide when farmland goes fallow, when sprinklers water crops, and when farmland dries out.
Looking Back
Here’s what the game looked like at the end of the first week.
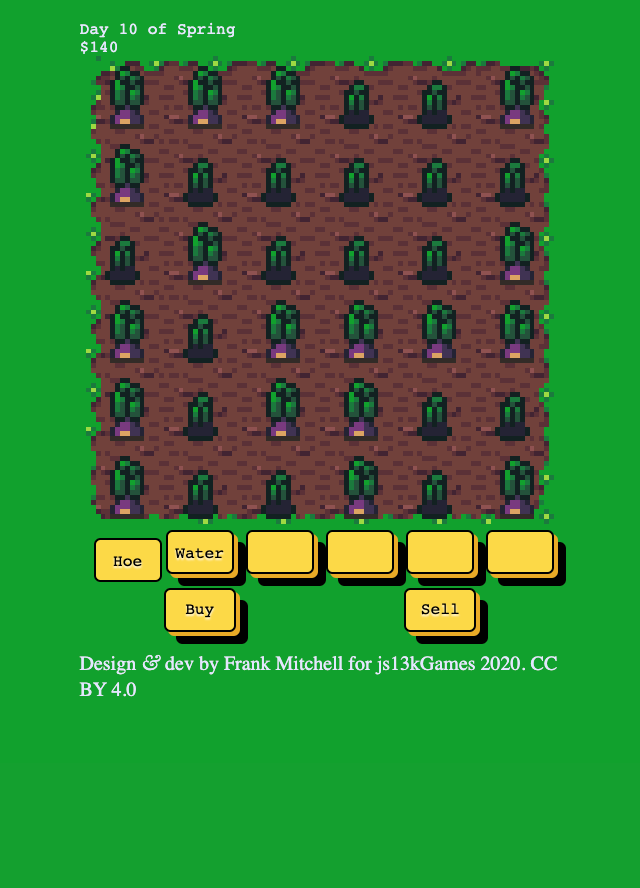
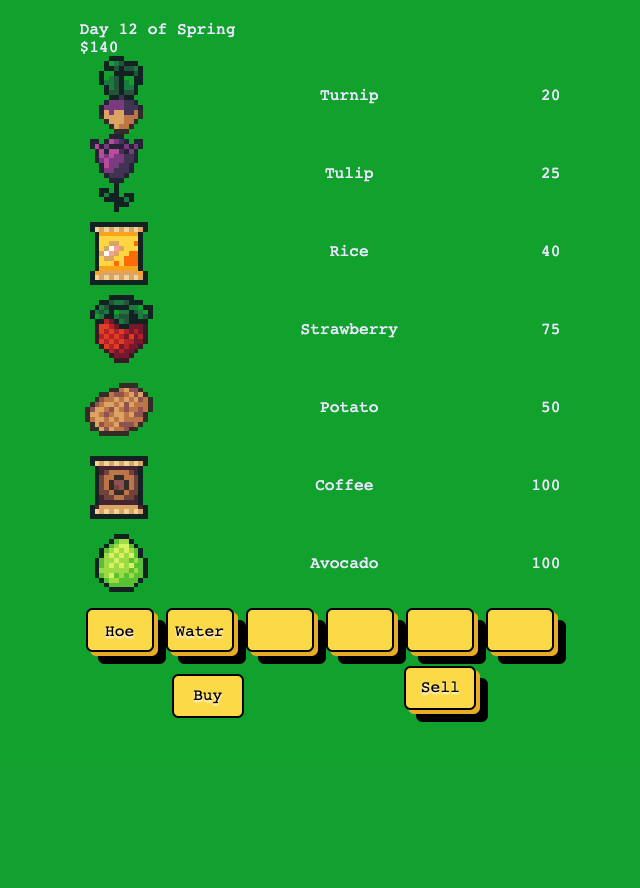

Week 2nd
One week into the competition I had a working game, but it wasn’t really fun. You could grow crops and sell them, but one spring harvest of turnips gave you more coins than you could reasonably spend. So I spent some time improving the graphics.
I styled the inventory bar, plus the Buy and Sell screens. A lot of the visual design for those was inspired by Stardew Valley. I added a hoe and watering can, plus an envelope to hold seeds, and sprinklers that automatically watered crops. It looked more polished, but it was still a very passive game.
Finding Fun
Dewdrop Farm is the first game I’ve made that didn’t start with me knowing what “Game Over” looked liked. There was just an never ending loop of crop gathering. Fortunately, Game Maker’s Toolkit posted a timely YouTube video about letting games design themselves. That got me thinking about what I liked about farming in SimFarm, and foraging in Stardew Valley, and mining in EVE Online. I realized I enjoyed the repetative task of gathering resouces, balanced with the threat of an external force taking those resources away.
The bunny in Dewdrop Farm is that external force. It hops around and undoes all your hard work. If it lands on a crop, it eats the crop. You can scare the bunny by poking it, making it hop toward the edge of the farm. If it’s on an edge when you poke it, it’ll hop off the farm, and you get a day without a bunny. But the bunny will be back the day after that.
That ended up being exactly the mechanic I needed. I found myself spending lots of time planting crops and nudging the bunny away from them instead of writing code.
Looking Back
Here’s what the game looked like at the end of the second week.

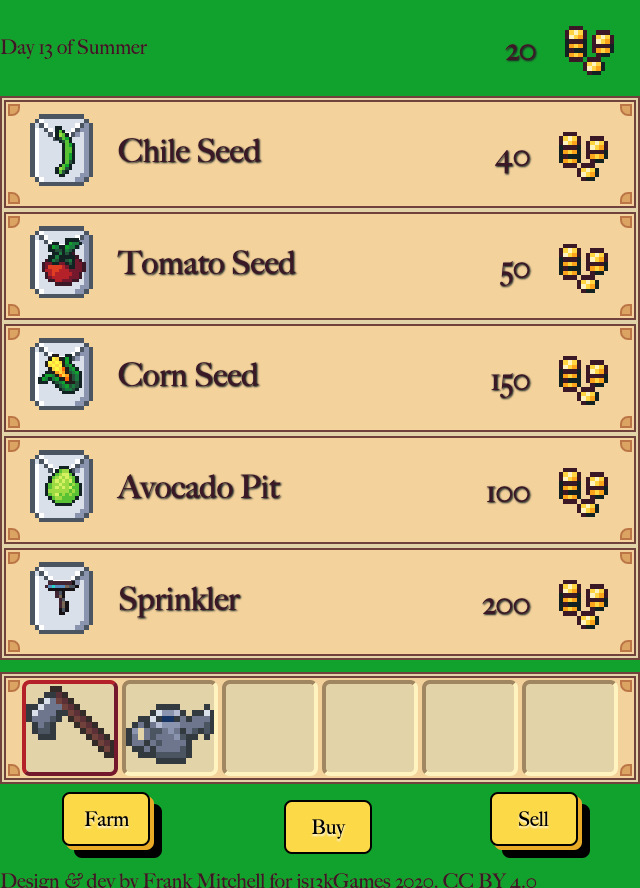
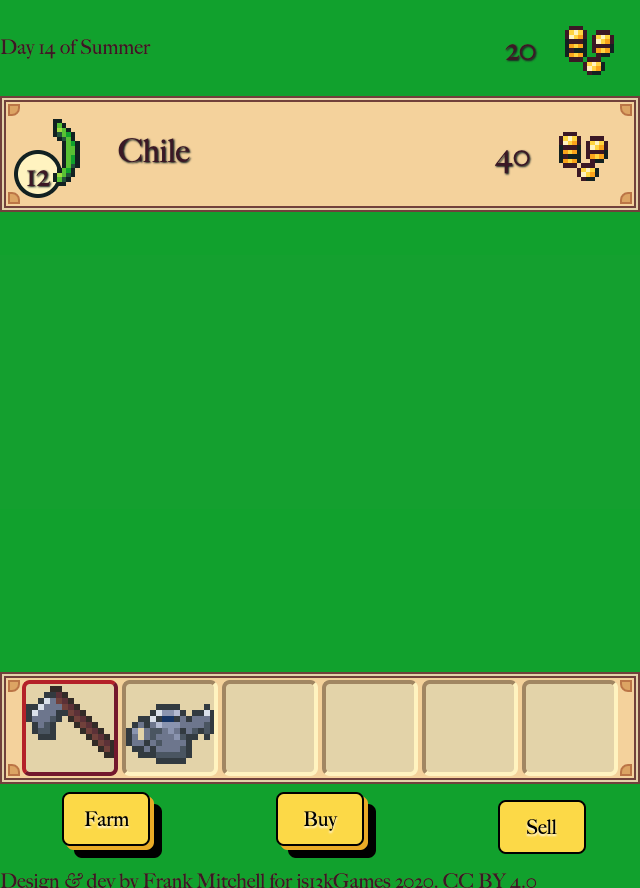
Week 3rd
I wanted Dewdrop Farm to be a game you could pick up and discover how to play.
The hoe is the active tool when you start. That lets you immediately click
farmland and have something happen. The “Buy” and “Sell” buttons are labeled
with verbs instead of the store and market nouns the code uses. That makes
their actions obvious. My playtesters all figured things out without any
gameplay hints, so I figure I did something right.
Managing Inventory
My original plan was that Dewdrop Farm wouldn’t have inventory limits. The four slots would be able to hold as many seeds as you could buy. Crops for sale would show up on the Sell screen, not in your inventory. But that was unsatisfying, because you didn’t see progress as you harvested crops. The graphics changed, but none of the visible numbers went up.
Also, I didn’t know what to do if the number of crops you had for sale or seeds you had in your inventory got really large. I needed to limit it so the counters on the seeds and crops wouldn’t obscure the image. So I capped it at 16 because that looked nice.
That ended up being a good number, because it means a field of seeds takes up a bit over half your inventory. So you need to make two trips to the Sell screen if you want a full field of fertilized crops. It also doesn’t divide evenly into 6, the length of a row on the farm, so you have to be a bit precise in your shopping if you want to plant rows of crops without leftover seeds.
Once I had inventory limits, I added logic to stop you from buying seeds or harvesting crops if they wouldn’t fit in your inventory. I didn’t want an accidental click to ruin hard work. The inventory fill algorithm comes from Minecraft. Slots are looped through from left to right. Items go in the first matching slot, or the first empty slot if there isn’t a matching slot. Items also sell from the inventory left to right.
To draw the Sell screen, I loop over the inventory items from left to right, and render a row for each. Like items stack, and when a row sells out, it vanishes. This allows you to sell an entire inventory of crops by continuously clicking the top button.
Clicking Around
One of the earliest mechanics I added was allowing you to click and drag to plant seeds, harvest crops, and water the farm. It makes playing on a desktop with a mouse a lot of fun. When I switched my testing to a laptop, I realized that clicking and dragging with a trackpad is quite a bit slower. So I added the keyboard shorcuts to make up for that. You can keep the cursor over the farm, and every clickable button you need is in that space.
I never figured out how to get touchmove events to register on a phone. It’s
something I’d like to solve in a post competition version. Mobile play is very
much an exercise in tapping, which has its own charm, but isn’t the experience
I wanted.
Once I realized buying seeds and selling crops was going to involve a lot of
clicking, I tried to find ways to make that enjoyable. I replayed Clicker Heroes
to remmber why button clicking felt fun there. Having buttons that animate on
mousedown and mouseup was key. Items also only buy or sell on mouseend
when the cursor is on the button. So you can cancel a purchase or sale by moving
the cursor off the button and letting go of the mouse.
I also made the coin graphic “animate” when items are bought and sold. I did that by fixing the left edge of the coin amount (the numbers) and bumping the coin graphic up against their right edge. Since the numbers in the Georgia font are variable width, the coin graphic moves a little bit back and forth when the numbers change.
Looking Back
Here’s what the game looked like at the end of the third week.
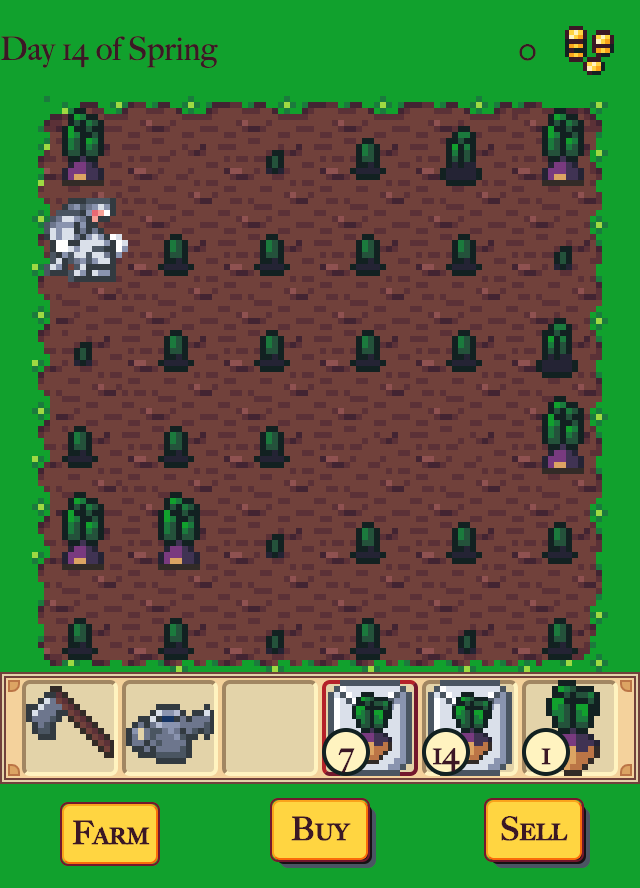
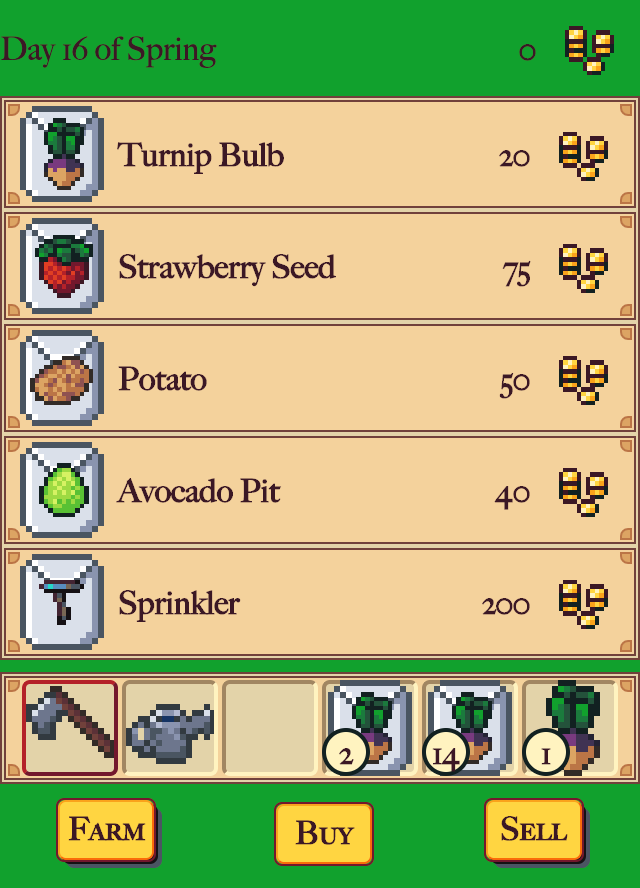
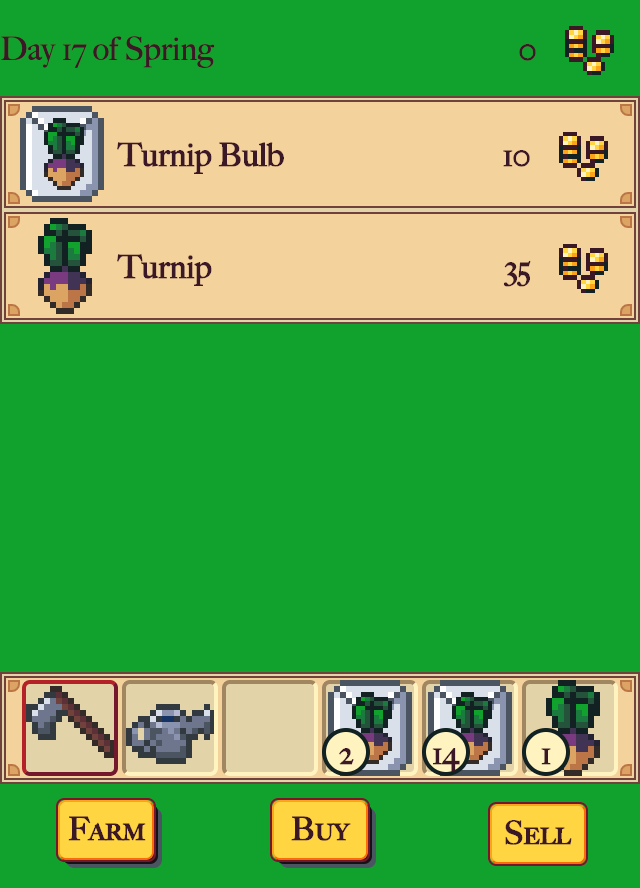
Week 4th
Changing Seasons
This is my favorite piece of code in Dewdrop Farm.
.magic { transition: background 22.5s linear; }
.spring { background: rgb(146, 220, 186); }
.summer { background: rgb(156, 219, 67); }
.fall { background: rgb(233, 181, 163); }
.winter { background: rgb(185, 191, 251); }
Those are the CSS rules that make the background colors change over the course of the first day of each season. I picked colors that are close in luminance to each other, because I didn’t want the screen brightness to change abrubtly.
Sarah Mitchell gave me a great accessibility testing tip, which was to play the game on my phone with the screen brightness turned all the way down. She prompted me to make the water texture brighter and to recolor all the seeds so they showed more contrast against the farmland.
I wanted an Animal Crossing: New Horizons kind of look to the water, droplets sprinkled on top of the crops. So they render over everything to keep them visible, and they’re randomly rotated to try and hide the fact there’s only one water graphic.
Optimizing Graphics
You’ll find some odd little experiments if you dig into the code, like png2code.js. That was my attempt to convert a PNG image into a run length encoded data format, that’s unpacked and rendered as a SVG inside the browser. For a long time during development, the farmland and crop graphics took up a ton of space. So I tried a bunch of things to try and shrink them down.
I started by putting all the graphics in a single image. Then I culled crops, cutting them down from the original 20 to a final 6. To keep some variety, I changed the seasons they’re buyable and growable in. Each growing season has one crop that’s unique to it, one crop that also appears in the season before it, and one crop that also appears in the season after it. That gave me three crops per season.
Each crop has a seed image, four growing stage images, and a harvested image. So six images per crop. But the wildflowers you can buy in winter all use the same seed and first three growing stage images. The last growing stage image is unique for each (tulip, rose, sunflower), and I reuse it for their harvested image. That let me add three more crops to the farm with only seven images.
Even those tricks weren’t enough though. What finally ended up working was three things. First, I manually repacked the images into a single vertical strip, placing similar looking images next to each other. That let the PNG compression algorithm save some bytes, because the pixels didn’t change much from one row to the next. A tall vertical strip ended up compressing a little bit better than a wide horizontal strip, and was also easier to edit. Second, I ran the image through ImageOptim.
I’m not sure what magic ImageOptim is doing under the covers, but it ended up compressing my image better than anything else I found. I wish there was a command line version, because it would be a lovely thing to bake into a build system.
The third thing I did was embed the image in a data URI in the CSS, and embed the CSS in the HTML. Those three thigns ended up saving 837 bytes. That gave me enough space to add the graphics and logic for the cow.

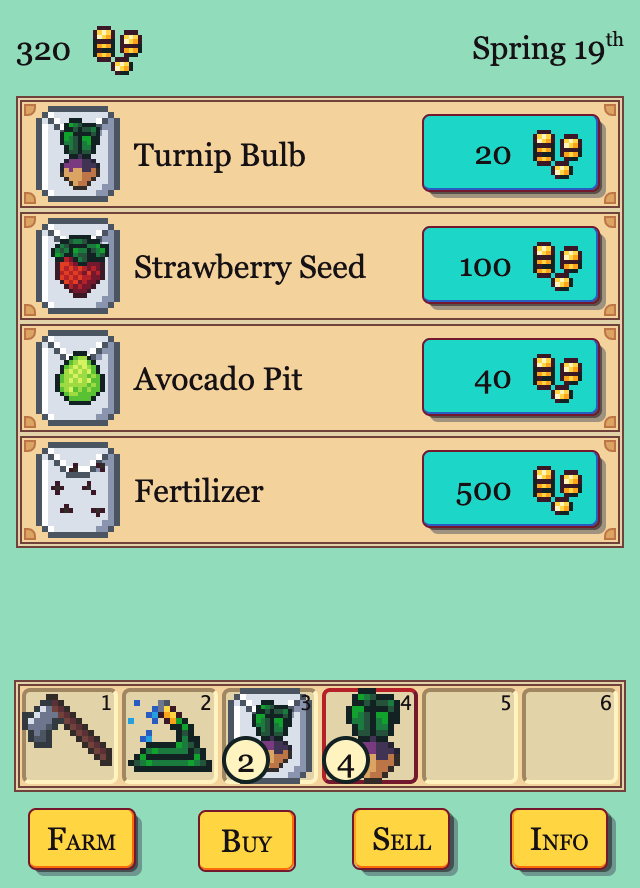
In many ways, buying the cow is very much the end game. At 150,000 coins, it looks like it will take a long time to get there. But eggplants have a 70 coin profit, and they show up in the fall next to the cow. My hope is that’s enough of a clue for players to figure out that you can keep playing through winter and get enough coins to buy the cow.
Looking Back
Here’s what the game looked like at the end of the fourth week.

Closing Thoughts
There’s a lot more I could say (and maybe will!) about Dewdrop Farm, but I’ve tried to limit this post-mortem to things that are unique to that game. All the mechanics of making a video game, putting graphics on the screen and changing them based on player input, are stuff I’ve written about in How to Make a Video Game. It’s the tutorial I wanted when I started making JavaScript games ten years ago. Give it a read, and maybe I’ll get to play your game in the next js13kGames competition.
Until then, happy farming!


